PGSQL Phriday #009: Three Big Ideas in Schema Evolution
I've used several migration frameworks in my time. Most have been variations on a common theme dating back lo these past fifteen-twenty years: an ordered directory of SQL scripts with an
sqitch: Orchestration
The first time I used sqitch, I screwed up by treating it like any other manager of an ordered directory of SQL scripts with fancier verification and release management capabilities. It does have those, but they weren't why I used sqitch the second and subsequent times.
sqitch wants you to treat your schema and the statements that define it as a supergraph of all your inter-database-object dependencies. Tables depend on types, on other tables via foreign keys, on functions with triggers or constraints; views depend on tables and functions; functions depend on tables, on other functions, on extensions. Each one, roughly, is a single named migration -- more on that in a bit.
So shipments depend on warehouses, since you have to have a source and a destination for the thing you're shipping, and warehouses depend on regions, because they exist at a physical address subject to various laws and business requirements. shipments also have no meaning independently from the thing being shipped, so in the case I'm filing the serial numbers from, that table also maintains a dependency on weather-stations. Both shipments and warehouses depend on the existence of the set_last_updated audit trigger function. The plan file looks like this:
trigger-set-updated-at 2020-03-19T17:20:30Z dian <> # trigger function for updated_at audit column
regions 2020-03-19T18:30:27Z dian <> # region/country lookup
warehouses [regions trigger-set-updated-at] 2020-03-20T16:34:56Z dian <> # storage for stuff
weather-stations [function-set-updated-at warehouses] 2020-03-20T17:46:36Z dian <> # stations!
shipping [warehouses weather-stations] 2020-03-20T18:56:49Z dian <> # move stuff aroundOr, for the more visually inclined:
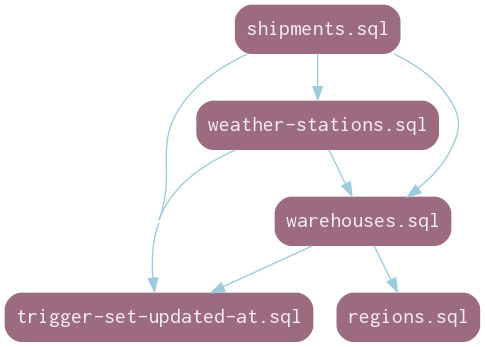
I have often kept tables and tightly coupled database objects such as types, junction tables, or (some) trigger functions in one file. Here, stations defines health and status types, a serial number sequence, and more, while warehouses includes a cluster of related tables representing inventory quantities.
There are two reasons behind this. First, I've mostly used sqitch on very small teams. If I'm the only person, or nearly the only person (I wrote 97% of the migrations in the weather-stations project) working on the database, the effort of factoring becomes pure overhead well before each database object has its own individual set of files.
Second, orchestration cuts both ways. Reworking and tracking the history of individual database objects is great as long as the changes stay local, but changes to a type or domain, for example, often involve a drop and replacement. The drop can't happen as long as there are columns of that type or domain anywhere else, so those have to be managed simultaneously. It's ugly no matter what, but in a linear "directory of scripts" framework, it's only as ugly as any other major change. Your script can create the new type, migrate dependent columns to it, drop the old type, and finally rename the new.
If you're using sqitch rigorously, the change is smeared across multiple sites and across time: rework the type to add the replacement, rework each dependent table to migrate its columns, tag, rework the type again to drop the old and rename the new, tag. Or you could hijack the typename.sql rework and do everything all at once in it -- undermining the sensible, well-delineated organization of schema objects that distinguishes sqitch in the first place. It's even worse when view dependencies change.
Using closely-related subgraphs instead of individual database objects as the "unit" of sqitch changes keeps many (not all) messy migrations contained, but there's no complete answer.
graphile-migrate: Idempotence
graphile-migrate is developed alongside but does not require Postgraphile, and hews a lot closer to the traditional directory-of-scripts style. Change scripts are numbered, checksummed, and validated per usual, but the development experience of graphile-migrate is unique.
Every other schema evolution framework I've used has expected me to run the next changeset once and only once on top of the previous and only the previous, even during active development. Any tweaks, fixes, or additions can't be applied until the database has been reset, whether by a revert or "down" migration, manually issuing DDL and deleting the run record from the change registry, or often as not dropping and recreating the dev database from scratch.
graphile-migrate expects you to run the migration you're actively working on over and over again. It even defaults to a file-watch mode which runs in the background and executes the "current" migration every time you save. I don't use that, because I save early and often, draft valid-but-destructive DDL with some frequency, and want to run tests, hence graphile-migrate watch --once && pg_prove; but the fact that executing the current migration just the one time is a special case kind of says it all.
It shouldn't matter whether you run the current migration once or a hundred times: the end database state must be identical. This can take some doing. On the easy side, it's always create or replace, never just create; but sometimes idempotent replacement isn't an option. Types and domains, constraints and options, row-level security policies, and more (views, if existing columns are changing) have to be handled with more care. And if not exists is a trap for the unwary.
create table if not exists warehouses (....) runs! The table is there, with the columns we've specified; next time we run the current migration, it skips warehouses seamlessly. It's great -- until we realize there's a column missing and add it in the create table definition, whereupon the next time we run the current migration, it skips warehouses seamlessly. The change needs to be this instead:
drop table if exists warehouses;
create table warehouses(....);In the case where warehouses was created in an already-committed migration and we need to add the column without dropping existing data, it's time to break out do blocks:
do $maybe_add_active$begin
alter table warehouses add column is_active boolean not null default true;
exception when duplicate_column then null;
end$maybe_add_active$;The official examples suggest scanning the system catalogs to determine whether to run a statement, but I've often found it quicker and easier to damn the torpedoes and trap specific exceptions afterward.
migra: Comparison
migra makes me nervous. This is the one I've never deployed, which is largely down to one specific but complicated reason: you don't write migrations (yay!), because it magically infers the necessary changes between old and new schemata (cool!), which means it maintains an internal model or map of Postgres features (stands to reason), which cannot be complete as long as Postgres is actively developed.
Is that necessary incompleteness really a dealbreaker? I actually think it shouldn't be! migra's goal is to save you all the time you formerly spent writing migration scripts at the hopefully-much-reduced cost of reviewing them and revising the tricky or unsupported bits. Its automated playbook doesn't have to be complete to make database development significantly faster.
A legitimate dealbreaker in some situations is that migra does not maintain a registry or even a history of valid schema states. There's only previous and next, with the latest revised diff between the two tracked in source control. It's theoretically feasible to pull all versions of the diff between t0 and tn and apply them one by one to reproduce the schema of a customer on a database dating back to that tn, but at that point you're setting all your other time savings on fire.
I haven't been in such a situation for some time, having had only one production database instance per project. Even so, when it's been up to me I've reached for a known quantity instead of investigating migra any further. Why? Because it isn't just a question of how completely migra supports Postgres features.
Complexity varies from database to database and from change to change. Something like migra could save tons of time on one database and not another, or even from one schema evolution to the next. It's hard to know whether you're in a migra-friendly scenario or not until you've already committed yourself, and the risk of falling out of that state and into writing complex migrations from scratch with next-to-no tool support doesn't go away.
It's a fantastic idea -- I should be able to reshape a database interactively, then generate at least an outline of a migration by comparing it to an unmodified baseline! Better still if I could test my change against that baseline and evaluate progress by the items remaining in the diff. The risks and the lack of history and verification keep me from using migra, but I hope we'll see its DNA in some of the next generation of schema evolution tools.